GritBot: An Informal Tutorial
"Grit" is a general term for small contaminants -- sand in food at the beach, foreign particles in gears, dust in one's eyes -- that can cause problems or discomfort. GritBot is a program that scans data to find implausible values or anomalies, a kind of "data grit". The presence of such anomalies compromises data quality and can also reduce the effectiveness of tools such as See5/C5.0 and Cubist that construct models from the data.
This short tutorial covers preparation of data for GritBot and the simple controls that influence its behavior.
In this tutorial, file names and GritBot input appear in
blue fixed-width font
while file extensions and other general forms
are shown highlighted in green.
Buttons and options on the Windows GUI are in maroon.
- Preparing Data for GritBot
- User Interface
- Scanning Data For Anomalies
- Inspecting New Data
- Running GritBot in Batch Mode
- Concluding Remarks
Preparing Data for GritBot
This section can be skimmed if you are familiar with preparing data for See5/C5.0 or Cubist, since GritBot accepts files for either system. Otherwise, read on ....
We will illustrate GritBot using a medical application -- an experimental database of thyroid assays obtained from the Garvan Institute of Medical Research in the early 1980s. Each case concerns a single referral and contains information on the source of the referral, assays requested, patient data, referring physician's comments, and one aspect of diagnosis (whether or not the patient suffers from hypothyroidism). Here are two examples:
Attribute Case 1 Case 2 ..... age 41 23 sex F F on thyroxine f f query on thyroxine f f on antithyroid medication f f sick f f pregnant f f thyroid surgery f f I131 treatment f f query hypothyroid f f query hyperthyroid f f lithium f f tumor f f goitre f f hypopituitary f f psych f f TSH 1.3 4.1 T3 2.5 2 TT4 125 102 T4U 1.14 unknown FTI 109 unknown referral source SVHC other diagnosis negative negative ID 3733 1442
GritBot exploits interdependencies among the attributes in order to identify possible anomalies in the data. The interdependencies are discovered by GritBot itself, so its operation is largely automatic.
Application files
Every GritBot application has a short name called a filestem; we will use the filestemhypothyroid
for this illustration.
All files read or written by GritBot for an application
have names of the form
filestem.extension,
where filestem identifies the application and
extension describes the contents of the file.
Here is a summary table of the extensions used by GritBot (to be described in later sections):
| names | description of the application's attributes | [required] |
| data | cases to be examined by GritBot | [required] |
| test | more cases to be examined by GritBot | [optional] |
| cases | yet more cases to be processed subsequently by GritBot | [optional] |
| sift | checks carried out by GritBot in a form that can be reused | [output] |
| grit or newgrit | report summarizing possible anomalies found by GritBot | [output] |
| list | case numbers of possibly anomalous records | [output] |
| gset | settings used for the last run | [output] |
APP.DATA,
app.data, and App.Data, are all different.
The extensions must be written
in lower case as shown above, otherwise GritBot will not recognize
the files for your application.
If GritBot cannot seem to find your files even though the filestem
and extensions are correct, please
check that file extensions are not hidden on your computer.
(If extensions are hidden and you write a text file from Wordpad,
it automatically adds an extension .txt that makes the file
invisible to GritBot.)
Names file
Two files are essential for all GritBot applications and there is one optional file. The first essential file is the names file (e.g.hypothyroid.names) that
describes the attributes.
There are two important subgroups of attributes:
- The value of an explicitly-defined attribute is given directly in the data. A discrete attribute has a value drawn from a set of nominal values, a continuous attribute has a numeric value, a date attribute holds a calendar date, a time attribute holds a clock time, a timestamp attribute holds a date and time, and a label attribute serves only to identify a particular case.
- The value of an implicitly-defined attribute is specified by a formula. (Most attributes are explicitly defined, so you may never need implicitly-defined attributes.)
The file hypothyroid.names looks like this:
diagnosis. | the target attribute for See5/C5.0 age: continuous. sex: M, F. on thyroxine: f, t. query on thyroxine: f, t. on antithyroid medication: f, t. sick: f, t. pregnant: f, t. thyroid surgery: f, t. I131 treatment: f, t. query hypothyroid: f, t. query hyperthyroid: f, t. lithium: f, t. tumor: f, t. goitre: f, t. hypopituitary: f, t. psych: f, t. TSH: continuous. T3: continuous. TT4: continuous. T4U: continuous. FTI:= TT4 / T4U. referral source: WEST, STMW, SVHC, SVI, SVHD, other. diagnosis: primary, compensated, secondary, negative. ID: label.
What's in a name?
Names, labels, and discrete values are represented by arbitrary strings of characters, with some fine print:- Tabs and spaces are permitted inside a name or value, but GritBot collapses every sequence of these characters to a single space.
- Special characters (comma, colon, period, vertical bar `
|') can appear in names and values, but must be prefixed by the escape character `\'. For example, the name "Filch, Grabbit, and Co." would be written asFilch\, Grabbit\, and Co\.
|'
causes the remainder of the line to be ignored and is handy for
including comments.
This use of `|' should not occur inside a name or value.
The first line of the names file is not used by GritBot but is included for compatibility with See5/C5.0 and Cubist. It specifies a target or dependent attribute for modeling, either by naming an attribute (See5/C5.0 or Cubist) or by listing two or more discrete class names (See5/C5.0 only). If you are preparing data for GritBot, just put here the name of any one of the attributes.
The attributes are then defined in the order that they will be given for each case.
Explicitly-defined attributes
The name of each explicitly-defined attribute is followed by a colon `:' and a description of the values taken by the attribute. There are six possibilities:
continuous- The attribute takes numeric values.
date- The attribute's values are dates in the form YYYY/MM/DD
or YYYY-MM-DD,
e.g.
1999/09/30or1999-09-30. Valid dates range from the year 1601 to the year 4000. time- The attribute's values are times in the form HH:MM:SS
with values between
00:00:00and23:59:59. timestamp- The attribute's values are times in the form
YYYY/MM/DD HH:MM:SS or
YYYY-MM-DD HH:MM:SS,
e.g.
1999-09-30 15:04:00. (Note that there is a space separating the date and time.) - a comma-separated list of names
- The attribute takes discrete values, and these are the allowable values.
The values may be prefaced by
[ordered]to indicate that they are given in a meaningful ordering, otherwise they will be taken as unordered. For instance, the valueslow, medium, highare ordered, whilemeat, poultry, fish, vegetablesare not. The former might be declared asgrade: [ordered] low, medium, high. discreteN for some integer N- The attribute has discrete, unordered values, but the values are assembled from the data itself; N is the maximum number of such values.
ignore- The values of the attribute should be ignored.
label- This attribute contains an identifying label for each case, such as an account number or an order code. The value of the attribute is ignored when the data is analyzed but is used when referring to individual cases. A label attribute can make it easier to locate format errors in the data and to identify possible anomalies. If there are two or more label attributes, only the last is used.
Attributes defined by formulas
The name of each implicitly-defined attribute is followed by `:=' and then a formula defining the attribute value. The formula is written in the usual way, using parentheses where needed, and may refer to any attribute defined before this one. Constants in the formula can be numbers (written in decimal notation), dates, times, and discrete attribute values (enclosed in string quotes `"'). The operators and functions that can be used in the formula are
-
+,-,*,/,%(mod),^(meaning `raised to the power') -
>,>=,<,<=,=,<>or!=(both meaning `not equal') -
and,or -
sin(...),cos(...),tan(...),log(...),exp(...),int(...)(meaning `integer part of')
FTI
above is continuous, since its value is obtained by dividing one number by
another. The value of a hypothetical attribute such as
strange := referral source = "WEST" or age > 40.
t or f
since the value given by the formula is either true or false.
If the value of the formula cannot be determined for a particular case because one or more of the attributes appearing in the formula have unknown values, the value of the implicitly-defined attribute is also unknown.
Dates, times, and timestamps
Dates are stored by GritBot as the number of days since a particular
starting point
so some operations on dates make sense.
Thus, if we have attributes
d1: date.
d2: date.
interval := d2 - d1.
gap := d1 <= d2 - 7.
d1-day-of-week := (d1 + 1) % 7 + 1.
interval then represents the number of days from
d1 to d2 (non-inclusive) and
gap would have a true/false value signaling whether
d1 is at least a week before d2.
The last definition is a slightly non-obvious way of determining
the day of the week on which d1 falls, with values
ranging from 1 (Monday) to 7 (Sunday).
Similarly, times are stored as the number of seconds since midnight.
If the names file includes
start: time.
finish: time.
elapsed := finish - start.
elapsed is the number of seconds
from start to finish.
Timestamps are a little more complex. A timestamp is rounded to
the nearest minute, but limitations on the precision of floating-point
numbers mean that the values stored for timestamps from more than
thirty years ago are approximate.
If the names file includes
departure: timestamp.
arrival: timestamp.
flight time := arrival - departure.
flight time is the number of minutes
from departure to arrival.
Selecting the attributes to be checked
An optional final entry in the names file affects the
way that GritBot checks the data. This entry takes one of
the forms
attributes included:
attributes excluded:
attributes excluded: sex, referral source.
sex and referral source
might still be used to describe a subset of cases containing an
anomalous value of another attribute.
Data file
The second essential file, the application's data file (e.g.hypothyroid.data)
provides information on the
cases that GritBot will check.
The entry for each case consists of one or more lines that give
the values for all explicitly-defined attributes.
Values are separated by commas and the entry is optionally terminated by
a period.
Once again, anything on a line after a vertical bar `|'
is ignored.
(If the information for a case occupies more than one line, make sure
that the line breaks occur after commas.)
The first two cases from file hypothyroid.data are:
41,F,f,f,f,f,f,f,f,f,f,f,f,f,f,f,1.3,2.5,125,1.14,SVHC,negative,3733
23,F,f,f,f,f,f,f,f,f,f,f,f,f,f,f,4.1,2,102,?,other,negative,1442
FTI
whose values are computed from other attribute values.
Notice that `?' is used to denote a value that is missing or unknown. Similarly, `N/A' denotes a value that is not applicable for a particular case. Also note that the cases do not contain values for the attribute FTI since its values are computed from other attribute values.
Test and cases files (optional)
The test file is optional and has exactly the same format as the data file. If it appears, GritBot will read cases from both the data and test files and analyze them together. A cases (e.g.hypothyroid.cases) is also
optional and has the same format. The cases file is discussed in
the section on inspecting new data below.
User Interface
Here is the main window of GritBot after the hypothyroid application has been selected.
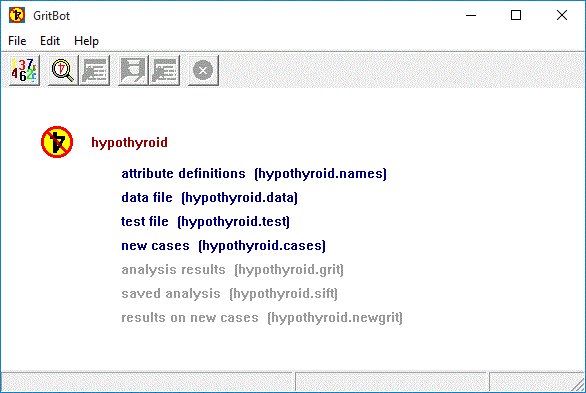
GritBot's main window has six buttons on its toolbar. From left to right, they are
- Locate Data
- invokes a browser to find the files for your application, or to change the current application;
- Check Data
- sets options and initiates data checking;
- Review Output
- re-displays the output from the last checking run for this application (if any)
- Inspect Data
- uses the analysis saved from the last checking run to check new data
- Review Output
- re-displays the output from the last inspection run
- Stop
- interrupts checking or inspection
The Edit menu facilities changes to the names file after an application's files have been located. On-line help is available through the Help menu.
Scanning Data For Anomalies
Once the names, data, and optional test files have been set up, everything is ready to use GritBot.The first step is to locate the application's files using the Locate Data button on the toolbar (or the corresponding selection from the File menu). We will assume that the hypothyroid application above has been located in this manner.
There are several parameters that affect GritBot's analysis. The Check Data button on the toolbar (or selection from the File menu) displays a dialog box for setting or changing their values:
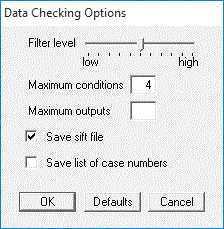
These parameters are discussed below, after we have looked at the basic operation of GritBot.
Default mode
When GritBot is invoked with the default values of the parameters, it produces output like this:
GritBot [Release 2.02] Tue Sep 22 19:09:46 2015
Options:
Application `hypothyroid'
Read 2772 cases (24 attributes) from hypothyroid.data
Read 1000 cases from hypothyroid.test
while checking age:
excluding 1 missing value
while checking sex:
excluding 150 missing values
while checking TSH:
excluding 369 missing values
excluding high tail (236 cases above 9.4)
while checking T3:
excluding 769 missing values
while checking TT4:
excluding 231 missing values
while checking T4U:
excluding 387 missing values
while checking FTI:
excluding 389 missing values
excluding low tail (49 cases below 36)
5 possible anomalies identified
data case 1365: (label 861) [0.002]
age = 455 (3771 cases, mean 52, 99.97% <= 94)
test case 373: (label 769) [0.006]
T3 = 7.6 (602 cases, mean 2.08, 99.8% <= 4)
TT4 > 83 and <= 155 [120]
T4U > 0.99 and <= 1.12 [1.04]
data case 2215: (label 2676) [0.008]
TSH = 8.5 (35 cases, mean 1.061, 34 <= 2.9)
FTI > 120.75 and <= 121.8 [121]
diagnosis in {secondary, negative} [negative]
data case 2224: (label 1562) [0.014]
age = 75 (53 cases, mean 32, 51 <= 42)
pregnant = t
data case 1610: (label 3023) [0.016]
age = 73 (53 cases, mean 32, 51 <= 42)
pregnant = t
Time: 0.4 secs
(A copy of this output is written to
filestem.grit, here
hypothyroid.grit.)
The first line identifies the version of GritBot and the run date.
GritBot reads 2772 cases from file hypothyroid.data
and a further 1000 from hypothyroid.test.
Some cases may have missing values or misleadingly
high/low values for some attributes,
and GritBot excludes these from the analysis
with a warning message.
For example, TSH has 369 missing values and 236 very high values
that might confuse the search for anomalies; all 605 cases are
excluded when GritBot searches for anomalous TSH values.
When the analysis is complete, GritBot identifies the possible anomalies that it has discovered; there are five for these data. A possible anomaly exists when a case's value for one attribute is surprising when compared with corresponding values for a subset of cases. Such an anomaly is reported in the following pattern:
case identification: [significance]Hereanomalous value (N cases, reason)
- The case is identified by its index in the application's data or test file. If a label attribute has been defined, its value is also shown here.
- The significance value estimates how likely it is that the anomalous value could occur by chance. Lower significance values imply greater certainty that a real anomaly has been found.
- The second line identifies the anomalous value and indicates why it is out of line with respect to the N cases in the subset. (GritBot considers only subsets for which N is at least 35 or 0.5% of the data, whichever is larger.)
- The subset itself is defined as the N cases satisfying all of the K conditions. Each condition refers to a single attribute and restricts the value of a numeric attribute or specifies one or more possible values for a discrete attribute. If there are no conditions, the value is anomalous with respect to the entire dataset.
The reason that a value appears anomalous takes two forms:
- mean M, X% <= value or
mean M, X% >= value - the case's value of a continuous attribute is either too high or two low with regard to the distribution of values for the subset
- X% `value'
- the case's value of a discrete attribute differs from the value common to almost all cases in the subset
- (When the number N of cases in the subset is small, X% is replaced by the relevant number of non-surprising cases.)
Conditions can take several forms:
- attribute = value
- the discrete attribute has a particular value
- attribute in value1 .. value2 [actual value]
- the ordered discrete attribute has a value in the subrange and the anomalous case's actual value is shown in square brackets
- attribute in {value1, value2, ... valueV} [actual value]
- the unordered discrete attribute has one of the values in the set and the anomalous case's actual value is shown in square brackets
- attribute <= value [actual value] or
attribute > value [actual value] or
attribute > value1 and <= value2 [actual value] - The continuous attribute has a value restricted as shown and the anomalous case's actual value is shown in square brackets
hypothyroid application
concerns case number 1365 in this application's
data file, and whose label is "861".
There are no conditions, so the subset consists of all 3771 cases
with known values of the attribute age.
This case has a patient age of 455, whereas 99.97% of the cases
-- all cases except this one --
have age values no greater than 94.
This is clearly anomalous!
The second possible anomaly illustrates subsets of cases characterized by more complex sets of conditions. There are 602 cases whose TT4 value lies between 83 and 155 and whose T4U value lies between 0.99 and 1.12. The average T3 value for these 602 cases is 2.08, and all cases except this one have values less than or equal to 4; this case's value of 7.6 is quite a bit larger. Of course, only an endocrinologist could judge whether this case is truly anomalous.
The last two possible anomalies pick out a couple of unlikely expectant mothers aged in their seventies. Once again, these are pretty clearly "data grit".
The final line shows the time taken for the analysis. This depends on the total number N of cases and the number A of attributes used to describe them; as a rule of thumb, the time to run GritBot varies roughly as N log(N) A2.
Filtering anomalies
The first parameter affecting GritBot's behavior is the filter level that governs the screening of possible anomalies. Lower values allow more possible anomalies to be found, while higher values filter them more actively and so reduce their number.The Check Data dialog box includes a slider for the filter level, with values ranging from low (0%) to high (100%). (The default value is 50%.) When the hypothyroid application is run with the lowest possible filter level (0%), 185 possible anomalies are reported. When the highest level (100%) is set, a single anomaly is reported (the patient aged 455).
Restricting the number of conditions
As we noted earlier, the subset of cases that forms the context of a possibly anomalous case is defined by zero or more conditions. GritBot incorporates a maximum conditions parameter to limit their number and so simplify the definition of subsets.The Check Data dialog box allows the maximum number of conditions to be altered. (The default value is 4.) Setting this parameter to 0 reports only cases that appear to be anomalous with respect to the entire dataset.
Allowing more conditions enables more complex subsets to be explored, generally at the cost of an increase in the time required to analyze a dataset.
Limiting the number of anomalies reported
After a very large dataset has been checked, the user may not wish to see a report showing thousands of possible anomalies!The Check Data dialog box allows the user to specify a maximum number of possible anomalies reported. If this box is blank, GritBot shows all possible anomalies that have been identified. GritBot still reports the total number found, but displays no more that the specified number of them.
Saving the analysis process
Checking a large dataset can take some time. If we receive new data for the same application, it could be checked by appending it to the existing data and re-running GritBot on the enlarged dataset. Another alternative, however, would be to check the new data using the information obtained when the original data was analysed.
By default, GritBot continually writes information to an ASCII file
filestem.sift (here
hypothyroid.sift).
This file summarizes the checks that GritBot makes in a form
that can be applied to new data. The sift file can
be quite large, however, and it will not be generated if
the save sift file box is unchecked.
Saving case numbers of possible anomalies
Having identified possible anomalies, the user might want to take some follow-up action. To facilitate this, GritBot can generate a simple ASCII file filestem.list (here
hypothyroid.list)
that contains the case numbers of the
possible anomalies found in serial order, one per line.
If both the data and test files
have been checked, a blank line is left between the case numbers for
the two files.
This option is invoked by checking the box shown.
For example, if the hypothyroid data is checked with this option enabled,
GritBot writes a file hypothyroid.list containing the
following information:
1365 1610 2215 2224 373(Notice the blank line between the last case number from the data file and the only case number from the test file.)
Inspecting New Data
As we noted above, GritBot can save the process found to check an application's data as a sift file that can be used to check new data for the same application.
The new data should be placed in the optional cases
file (here hypothyroid.cases).
The inspection process is initiated by the Inspect
button ![]() on the toolbar
or the corresponding action from the File menu.
(This button is activated only when the required sift
and cases files are present.)
The output is written to yet another file
filestem
on the toolbar
or the corresponding action from the File menu.
(This button is activated only when the required sift
and cases files are present.)
The output is written to yet another file
filestem.newgrit.
To illustrate this process, 500 new cases
have been placed in hypothyroid.cases.
These cases also come from the Garvan Institute and have
exactly the same format as the data and test
files.
The inspection process yields the following results:
GritBot Inspector [Release 2.02] Tue Sep 22 19:32:12 2015
Options:
Application `hypothyroid'
Read saved analysis from hypothyroid.sift
Read 500 cases (24 attributes) from hypothyroid.cases
6 possible anomalies identified
case 295: (label 4294) [0.002]
TSH = 1.9 (37 cases, mean 0.077, 36 <= 0.25)
sex = F
FTI > 172 and <= 189.8 [180]
diagnosis in {secondary, negative} [negative]
case 266: (label 4265) [0.004]
T3 = 9.5 (813 cases, mean 1.9, 100.0% <= 4.5)
TT4 > 88 and <= 105 [90]
case 433: (label 4432) [0.008]
TT4 = 4 (225 cases, mean 101.7, 100.0% >= 22)
query hypothyroid = t
case 189: (label 4188) [0.009]
TT4 = 4.06 (225 cases, mean 101.7, 100.0% >= 22)
query hypothyroid = t
case 380: (label 4379) [0.009]
FTI = 263 (44 cases, mean 122.55, 44 <= 178)
TT4 > 76 and <= 91 [84]
T4U <= 0.73 [0.32]
case 234: (label 4233) [0.016]
age = 73 (53 cases, mean 32, 51 <= 42)
pregnant = t
Time: 0.0 secs
Six possible anomalies are detected in the new cases. It is
worth noting that the third and fourth have no counterparts
in the possible anomalies detected in the original data --
that is, inspection of new cases can uncover
new kinds of anomalies.
The sift file includes all patterns found in the
analysis, even if these patterns revealed no anomalous cases in
the original data.
It is generally much faster to use a sift file to identify possible anomalies than to perform the analysis from scratch.
Running GritBot in Batch Mode
The GritBot distribution includes two programs GritBotX
and InspectX that
can be used to check data non-interactively.
These console applications reside in the same folder as GritBot
(by default C:\Program Files\GritBot
The command to run a GritBot initial check is:
start /B GritBotX -f filestem parameters
where the parameters enable one or more options discussed above to
be selected:
-l percent
| set the filter level |
-c conditions
| set the maximum number of conditions in a context |
-n anomalies
| set the maximum number of anomalies reported |
-s
| do not save checks in a sift file |
-r
| record case numbers in a list file |
-h
| print a summary of the GritBotX batch options |
start /B InspectX -f filestem parameters
where the optional parameters here are:
-n anomalies
| set the maximum number of anomalies reported |
-r
| record case numbers in a list file |
-h
| print a summary of the InspectX batch options |
If desired, output from GritBot can be diverted to a file in the usual way.
As an example, typing the commands
cd "C:\Program Files\GritBot"
start /B GritBotX -f Samples\anneal -c 5 >save.txt
save.txt.
Concluding Remarks
When it analyzes data, GritBot uses several heuristics or rules of thumb to define interesting subsets and to identify potentially anomalous values. GritBot cannot guarantee to find all anomalies in a dataset, and the cases that it reports are only possible anomalies.After a real anomaly is found, it is good practice to try to establish its cause. Was the value recorded incorrectly, or were digits transposed when entering the value? Did an instrument give a faulty reading? Are certain numeric values used as codes (a common one being to record an unknown value as zero)? Tracking the source of an anomaly in this way can help to improve future data quality.
| © RULEQUEST RESEARCH 2015 | Last updated September 2015 |
| home | products | licensing | download | contact us |